

Although you may have heard of the term “SEO measures,” you may have never heard of the terms “crawling” or “crawler.”
SEO measures are ways to make your company’s website appear higher when a user searches for a certain keyword on a search engine. A crawler is a robot that collects elements from a site that search engines use to determine search rankings.
SEO measures include measures to ensure that this crawler collects information about your site correctly, so in order to properly understand SEO measures, you also need to know about crawlers. This time, we will introduce how search engines work and crawlers.
How search engines work
Do you think “SEO measures can be left to the web staff”? Nowadays, your own website and
search engine
are essential elements for your business. If you don’t even understand the outline of the language, you won’t be able to participate in the meeting. First, let’s take a quick look at how search engines work.
Search engine is a general term for services that search for content on the Internet, such as Google and Yahoo. In the early days of the Internet, the “directory type” system, in which site information was collected manually and classified into categories, was the mainstream, but now it has evolved into a type known as the “robot type.”

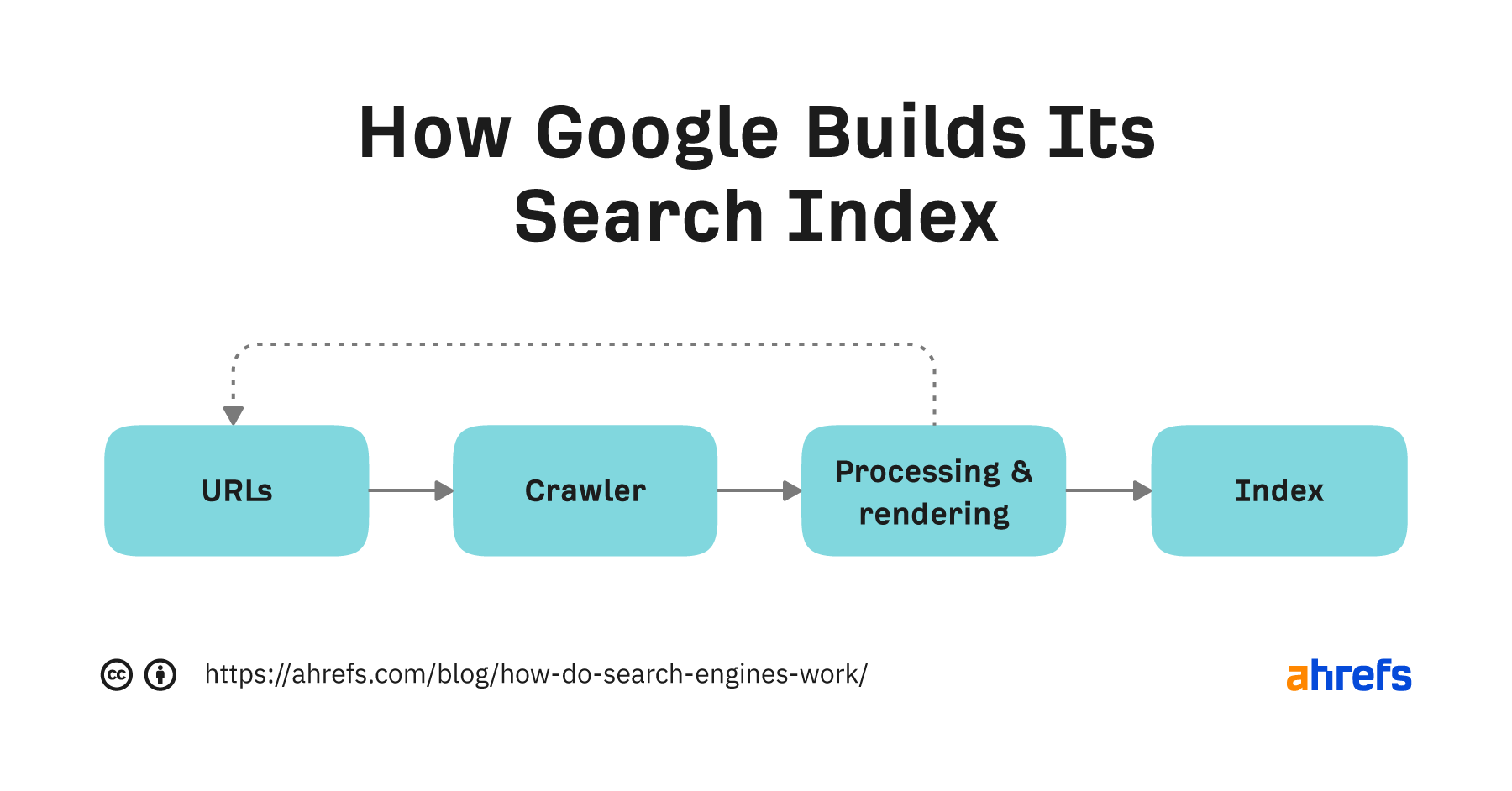
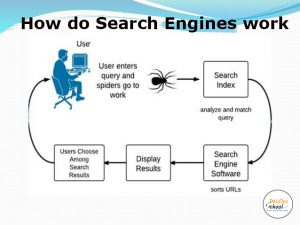
The robotic search engine consists of three programs.
- A program called a robot or crawler that collects website information (HTML, images, etc.) and creates a database.
- A program that analyzes and evaluates (ranks) the information collected by crawlers.
- A program that displays search results (search ranking) based on the evaluation of keywords entered on search sites.

A search engine is a system in which the above programs work together to present search results to users.
What is a crawler?

As mentioned above, a crawler is a robot (
bot
) that crawls around a site and collects the elements that search engines use to determine search rankings. It gets its name from the word “crawl”, which means to crawl.
There are different types of crawlers for each search engine. For example, Google uses Googlebot, Bing uses Bingbot, and China’s Baidu uses a crawler called Baiduspider. There are also crawlers for SEO tools and crawlers for AI assistants (AppleBot).
Among them, Google has the highest market share in the world as a search engine, with a market share of over 80% in Japan. Yahoo Japan also uses Google’s search engine, and most of the various measures against crawlers are aimed at Googlebot.
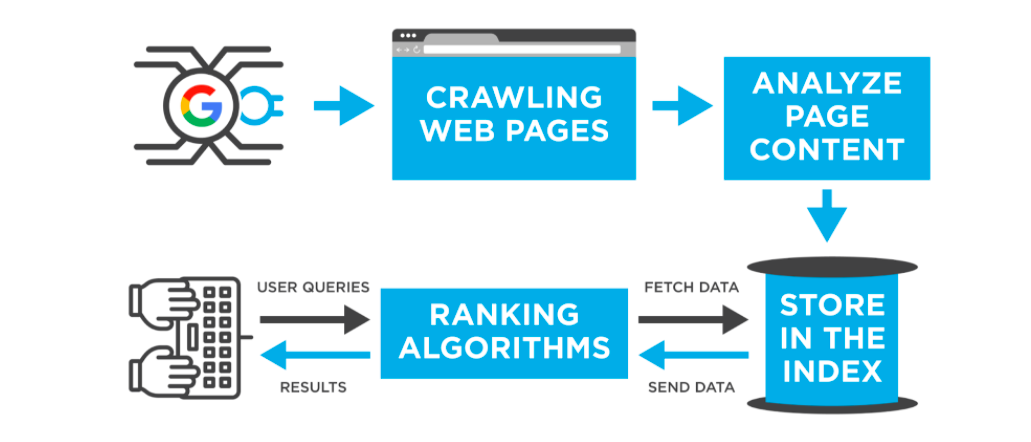
Crawlers automatically move (crawl) by following links from websites that have already been compiled into a database. At the destination, the page will be analyzed (parsed), the following files will be collected, converted into data that can be easily handled by the search algorithm, and the results will be registered in the database.
- HTML
- text file
- CSS file
- JavaScript file
- image
Sites that are never visited by crawlers and the above files are not collected will naturally not be displayed on search engines. In such cases, no matter how much SEO you do, it will be in vain. The first step in SEO is to create a site that is easily searchable by crawlers.

To make it easier for crawlers to search
Making it easier for crawlers to search is called improving crawlability.
Generally, it is said that crawlability can be improved by taking the following measures. Here, we will explain the case of Google as an example.
- Request a crawl from Google
For Google, you can request crawling. This is the most reliable way to improve crawlability. Specifically, the request is made using a feature called “URL inspection” from a free tool called Google Search Console. It will be crawled quickly when you create a new site or update content.
- URL normalization (review of duplicate content)
Some website URLs include “www.” and some do not. Two URLs on the same page are considered duplicate content and will be crawled less frequently. Unify multiple URLs into one.
- Limit the URL hierarchy to three levels

All pages are designed so that they can be accessed with two clicks from the top page. Googlebot prioritizes crawling pages that are shallow, so this strategy makes it easier for all pages to be crawled.
- Set the link as text
Although you may often link by clicking on an image, crawlability will be improved if you link by text.
There are many other ways to improve crawlability, but the algorithms of Google and other crawlers change irregularly. Since the same improvement measures from the past are not always applicable today, it is recommended to regularly consult with a company specializing in SEO to improve crawlability.

summary

◆A crawler is a robot that collects elements from a site that are used by search engines to determine search rankings.
◆Search Engine is a general term for services that search for content on the Internet, such as Google and Yahoo.
◆Search engines used to be mainly directory-type, in which search engines were registered manually, but now they are mostly robot-type, which use crawlers.
◆Robotic search engines use crawlers to collect information from websites and create a database. Search rankings are determined by a program that ranks the information.
◆There are multiple ways to improve crawlability to make it easier for crawlers to search, but crawler algorithms change irregularly. It is advisable to continuously improve crawlability while consulting with an SEO specialist company.